

-


移动开发
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 白羽
2018-06-27
来源 :网络
阅读 1445
评论 0
白羽
2018-06-27
来源 :网络
阅读 1445
评论 0
摘要:本文将带你了解Android开发中 XML 数据解析,希望本文对大家学Android有所帮助。
Android 中 XML 数据解析详解
今天我们来学习另一种非常重要的数据交换格式-XML。XML(Extensible Markup Language的缩写,意为可扩展的标记语言),它是一种元标记语言,即定义了用于定义其他特定领域有关语义的、结构化的标记语言,这些标记语言将文档分成许多部件并对这些部件加以标识。XML 文档定义方式有:文档类型定义(DTD)和XML Schema。DTD定义了文档的整体结构以及文档的语法,应用广泛并有丰富工具支持。XML Schema用于定义管理信息等更强大、更丰富的特征。XML能够更精确地声明内容,方便跨越多种平台的更有意义的搜索结果。它提供了一种描述结构数据的格式,简化了网络中数据交换和表示,使得代码、数据和表示分离,并作为数据交换的标准格式,因此它常被称为智能数据文档。
由于XML具有很强的扩展性,致使它需要很强的基础规则来支持扩展,所以在编写XML文件时,我们应该严格遵守XML的语法规则,一般XML语法有如下规则:(1)起始和结束的标签相匹配;(2)嵌套标签不能相互嵌套;(3)区分大小写。下面是给出了一个编写错误的XML文件以及对其的错误说明,如下:
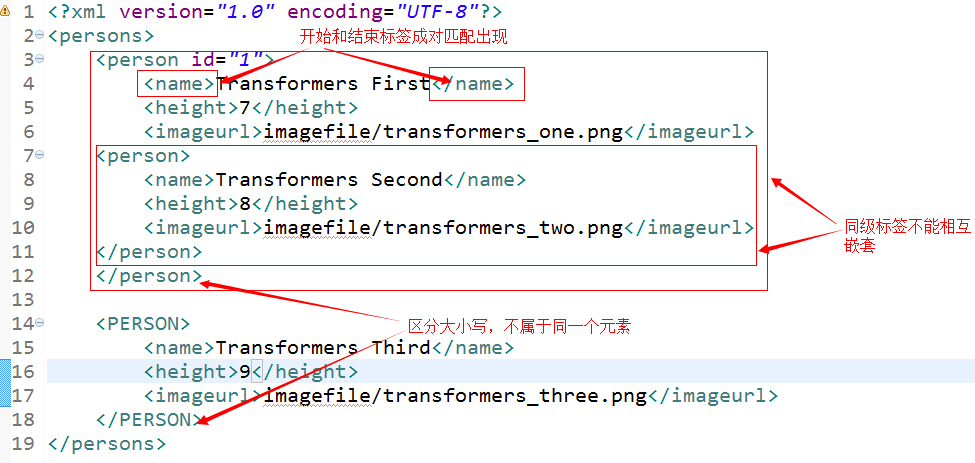
本文只是对XML做了个简单的介绍,要想学习更多有关XML知识,可以访问如下网站://bbs.xml.org.cn/index.asp。
XML在实际应用中比较广泛,Android也不例外,作为承载数据的重要角色,如何读写XML称为Android开发中一项重要的技能。
Android中XML数据解析使用实例
在Android开发中,较为常用的XML解析器有SAX解析器、DOM解析器和PULL解析器,下面我们将会一一学习如何使用这些XML解析器。那在介绍这几种XML解析器过程中,我们依然是要通过一个实例来学习它们的实际开发方法,下面是我们Demo实例的程序列表清单,如下:
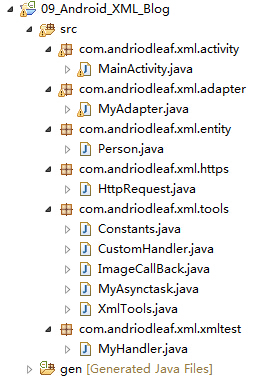
图1-1 客户端
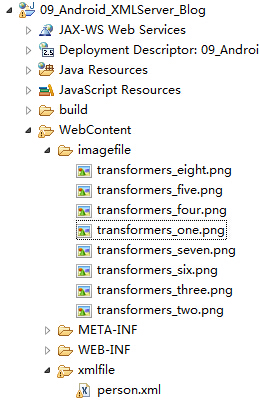
图1-2 服务器端
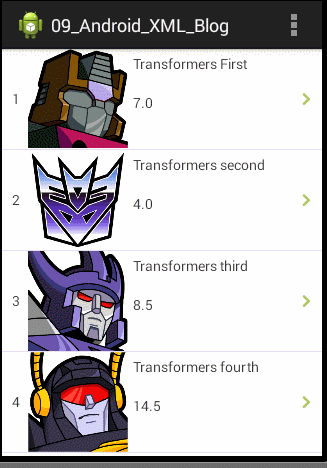
来整理下我们实现的Demo实例思路:客户端通过网络请求读取服务器端的person.xml,person.xml文件中的内容如下:
<?xml version="1.0" encoding="UTF-8"?> <persons>
<person id="1">
<name>Transformers First</name>
<height>7</height>
<imageurl>imagefile/transformers_one.png</imageurl>
</person>
<person id="2">
<name>Transformers second</name>
<height>4</height>
<imageurl>imagefile/transformers_two.png</imageurl>
</person>
<person id="3">
<name>Transformers third</name>
<height>8.5</height>
<imageurl>imagefile/transformers_three.png</imageurl>
</person>
<person id="4">
<name>Transformers fourth</name>
<height>14.5</height>
<imageurl>imagefile/transformers_four.png</imageurl>
</person>
<person id="5">
<name>Transformers fifth</name>
<height>27.5</height>
<imageurl>imagefile/transformers_five.png</imageurl>
</person>
<person id="6">
<name>Transformers Sixth</name>
<height>8.5</height>
<imageurl>imagefile/transformers_six.png</imageurl>
</person>
<person id="7">
<name>Transformers Seventh</name>
<height>5</height>
<imageurl>imagefile/transformers_seven.png</imageurl>
</person>
<person id="8">
<name>Transformers Eighth</name>
<height>12.5</height>
<imageurl>imagefile/transformers_eight.png</imageurl>
</person> </persons>
接着将获取到的person.xml的文件流信息分别使用SAX、DOM和PULL解析方式解析成Java对象,然后将解析后获取到的Java对象信息以列表的形式展现在客户端,思路很简单吧。
好了,基本了解了Demo实例的整体思路后,接下来我们将学习如何具体实现它们。
SAX解析XML文件实例
SAX(Simple For XML)是一种基于事件的解析器,它的核心是事件处理模式,它主要是围绕事件源和事件处理器来工作的。当事件源产生事件后,会调用事件处理器中相应的方法来处理一个事件,那在事件源调用对应的方法时也会向对应的事件传递一些状态信息,以便我们根据其状态信息来决定自己的行为。
接下来我们将具体地学习一下SAX解析工作的主要原理:在读取XML文档内容时,事件源顺序地对文档进行扫描,当扫描到文档的开始与结束(Document)标签、节点元素的开始与结束(Element)标签时,直接调用对应的方法,并将状态信息以参数的形式传递到方法中,然后我们可以依据状态信息来执行相关的自定义操作。为了更好的理解SAX解析的工作原理,我们结合具体的代码来更深入的理解下,代码如下:
/**
* SAX解析类
* @author AndroidLeaf
*/ public class MyHandler extends DefaultHandler {
//当开始读取文档标签时调用该方法
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
}
//当开始读取节点元素标签时调用该方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
super.startElement(uri, localName, qName, attributes);
//do something
}
//当读取节点元素的子类信息时调用该方法
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
super.characters(ch, start, length);
//do something
}
//当结束读取节点元素标签时调用该方法
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
//do something
}
//当结束读取文档标签时调用该方法
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
//do something
}
}
首先我们先认识一个重要的类–DefaultHandler,该类是XML解析接口(EntityResolver, DTDHandler, ContentHandler, ErrorHandler)的缺省实现,在通常情况下,为应用程序扩展DefaultHandler并覆盖相关的方法要比直接实现这些接口更容易。接着重写startDocument(),startElement(),characters(),endElement和endDocument()五个方法,这些方法会在事件源(在org.xml.sax包中的XMLReader,通过parser()产生事件)读取到不同的XML标签所产生事件时调用。那我们开发时只要在这些方法中实现我们的自定义操作即可。下面总结罗列了一些使用SAX解析时常用的接口、类和方法:
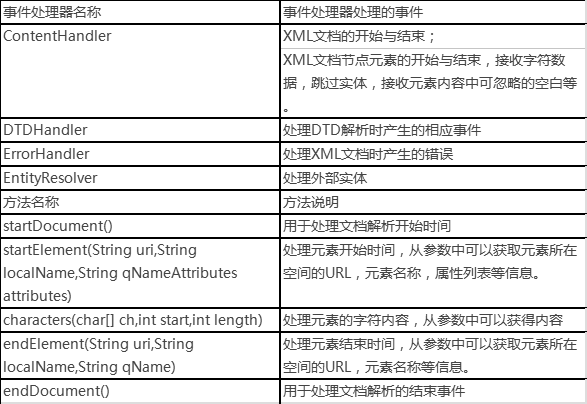
基本了解完SAX解析工作原理及开发时用到的常用接口和类后,接下来我们来学习一下使用SAX解析XML的编程步骤,一般分为5个步骤,如下:
1、获取创建一个SAX解析工厂实例;
2、调用工厂实例中的newSAXParser()方法创建SAXParser解析对象;
3、实例化CustomHandler(DefaultHandler的子类);
4、连接事件源对象XMLReader到事件处理类DefaultHandler中;
5、通过DefaultHandler返回我们需要的数据集合。
接着,我们按照这5个步骤来完成Demo实例解析person.xml的工作(person.xml的内容上面已经列出),解析的关键代码是在Demo实例工程中的XmlTools类中,具体代码如下:
/**--------------SAX解析XML-------------------*/
/**
* @param mInputStream 需要解析的person.xml的文件流对象
* @param nodeName 节点名称
* @return mList Person对象集合
*/
public static ArrayList<Person> saxAnalysis(InputStream mInputStream,String nodeName){
//1、获取创建一个SAX解析工厂实例
SAXParserFactory mSaxParserFactory = SAXParserFactory.newInstance();
try {
//2、调用工厂实例中的newSAXParser()方法创建SAXParser解析对象
SAXParser mSaxParser = mSaxParserFactory.newSAXParser();
//3、实例化CustomHandler(DefaultHandler的子类)
CustomHandler mHandler = new CustomHandler(nodeName);
/**
* 4、连接事件源对象XMLReader到事件处理类DefaultHandler中
* 查看parse(InputStream is, DefaultHandler dh)方法源码如下:
* public void parse(InputSource is, DefaultHandler dh)
* throws SAXException, IOException {
* if (is == null) {
* throw new IllegalArgumentException("InputSource cannot be null");
* }
* // 获取事件源XMLReader,并通过相应事件处理器注册方法setXXXX()来完成的与ContentHander、DTDHander、ErrorHandler,
* // 以及EntityResolver这4个接口的连接。
* XMLReader reader = this.getXMLReader();
* if (dh != null) {
* reader.setContentHandler(dh);
* reader.setEntityResolver(dh);
* reader.setErrorHandler(dh);
* reader.setDTDHandler(dh);
* }
* reader.parse(is);
* }
*/
mSaxParser.parse(mInputStream, mHandler);
//5、通过DefaultHandler返回我们需要的数据集合
return mHandler.getList();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
事件处理器类CustomerHandler中的具体代码如下:
/**
* SAX解析类
* @author AndroidLeaf
*/ public class CustomHandler extends DefaultHandler {
//装载所有解析完成的内容
List<HashMap<String, String>> mListMaps = null;
//装载解析单个person节点的内容
HashMap<String, String> map = null;
//节点名称
private String nodeName;
//当前解析的节点标记
private String currentTag;
//当前解析的节点值
private String currentValue;
public ArrayList<Person> getList(){
ArrayList<Person> mList = new ArrayList<Person>();
if(mListMaps != null && mListMaps.size() > 0){
for(int i = 0;i < mListMaps.size();i++){
Person mPerson = new Person();
HashMap<String, String> mHashMap = mListMaps.get(i);
mPerson.setId(Integer.parseInt(mHashMap.get("id")));
mPerson.setUserName(mHashMap.get("name"));
mPerson.setHeight(Float.parseFloat(mHashMap.get("height")));
mPerson.setImageUrl(mHashMap.get("imageurl"));
mList.add(mPerson);
}
}
return mList;
}
public CustomHandler(String nodeName){
this.nodeName = nodeName;
}
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
mListMaps = new ArrayList<HashMap<String, String>>();
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
if (qName.equals(nodeName)) {
map = new HashMap<String, String>();
}
if (map != null && attributes != null) {
for (int i = 0; i < attributes.getLength(); i++) {
map.put(attributes.getQName(i), attributes.getValue(i));
}
}
// 当前的解析的节点名称
currentTag = qName;
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
if (map != null && currentTag != null) {
currentValue = new String(ch, start, length);
if (currentValue != null && !currentValue.equals("")
&& !currentValue.equals("\n")) {
map.put(currentTag, currentValue);
}
}
currentTag = null;
currentValue = null;
super.characters(ch, start, length);
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// TODO Auto-generated method stub
if (qName.equals(nodeName)) {
mListMaps.add(map);
map = null;
}
super.endElement(uri, localName, qName);
}
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
}
}
CustomerHandler通过不断接收事件源传递过来的事件,进而执行相关解析工作并调用对应的方法,然后以参数的形式接收解析结果。
DOM解析XML文件实例
DOM是基于树形结构的的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树、检索所需数据。分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息。Android完全支持DOM 解析。利用DOM中的对象,可以对XML文档进行读取、搜索、修改、添加和删除等操作。
DOM的工作原理:使用DOM对XML文件进行操作时,首先要解析文件,将文件分为独立的元素、属性和注释等,然后以节点树的形式在内存中对XML文件进行表示,就可以通过节点树访问文档的内容,并根据需要修改文档——这就是DOM的工作原理。DOM实现时首先为XML文档的解析定义一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,这样代码就可以使用DOM接口来操作整个树结构。由于DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。 当然,如果XML文件的内容比较小,采用DOM是可行的。下面罗列了一些使用DOM解析时常用的接口和类,如下:
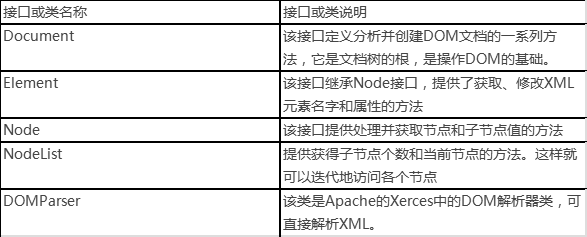
接下来我们学习一下使用DOM解析XML的编程步骤,一般分为6个步骤,如下:
1、创建文档对象工厂实例;
2、调用DocumentBuilderFactory中的newDocumentBuilder()方法创建文档对象构造器;
3、将文件流解析成XML文档对象;
4、使用mDocument文档对象得到文档根节点;
5、根据名称获取根节点中的子节点列表;
6 、获取子节点列表中需要读取的节点信息。
然后,我们按照这6个步骤来完成Demo实例解析person.xml的工作(person.xml的内容上面已经列出),解析的关键代码是在Demo实例工程中的XmlTools类中,具体代码如下:
/**--------------DOM解析XML-------------------*/
/**
* @param mInputStream 需要解析的person.xml的文件流对象
* @return mList Person对象集合
*/
public static ArrayList<Person> domAnalysis(InputStream mInputStream){
ArrayList<Person> mList = new ArrayList<Person>();
//1、创建文档对象工厂实例
DocumentBuilderFactory mDocumentBuilderFactory = DocumentBuilderFactory.newInstance();
try {
//2、调用DocumentBuilderFactory中的newDocumentBuilder()方法创建文档对象构造器
DocumentBuilder mDocumentBuilder = mDocumentBuilderFactory.newDocumentBuilder();
//3、将文件流解析成XML文档对象
Document mDocument = mDocumentBuilder.parse(mInputStream);
//4、使用mDocument文档对象得到文档根节点
Element mElement = mDocument.getDocumentElement();
//5、根据名称获取根节点中的子节点列表
NodeList mNodeList = mElement.getElementsByTagName("person");
//6 、获取子节点列表中需要读取的节点信息
for(int i = 0 ;i < mNodeList.getLength();i++){
Person mPerson = new Person();
Element personElement = (Element) mNodeList.item(i);
//获取person节点中的属性
if(personElement.hasAttributes()){
mPerson.setId(Integer.parseInt(personElement.getAttribute("id")));
}
if(personElement.hasChildNodes()){
//获取person节点的子节点列表
NodeList mNodeList2 = personElement.getChildNodes();
//遍历子节点列表并赋值
for(int j = 0;j < mNodeList2.getLength();j++){
Node mNodeChild = mNodeList2.item(j);
if(mNodeChild.getNodeType() == Node.ELEMENT_NODE){
if("name".equals(mNodeChild.getNodeName())){
mPerson.setUserName(mNodeChild.getFirstChild().getNodeValue());
}else if("height".equals(mNodeChild.getNodeName())){
mPerson.setHeight(Float.parseFloat(mNodeChild.getFirstChild().getNodeValue()));
}else if("imageurl".equals(mNodeChild.getNodeName())){
mPerson.setImageUrl(mNodeChild.getFirstChild().getNodeValue());
}
}
}
}
mList.add(mPerson);
}
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return mList;
}
PULL解析XML文件实例
PULL的解析方式与SAX解析类似,都是基于事件的模式。不同的是,在PULL解析过程中返回的是数字,且我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法,执行我们的代码。PULL 的工作原理:XML pull提供了开始元素和结束元素。当某个元素开始时,我们可以调用parser.nextText从XML文档中提取所有字符数据。当解释到一个文档结束时,自动生成EndDocument事件。下面罗列了一些使用PULL解析时常用的接口、类和方法:
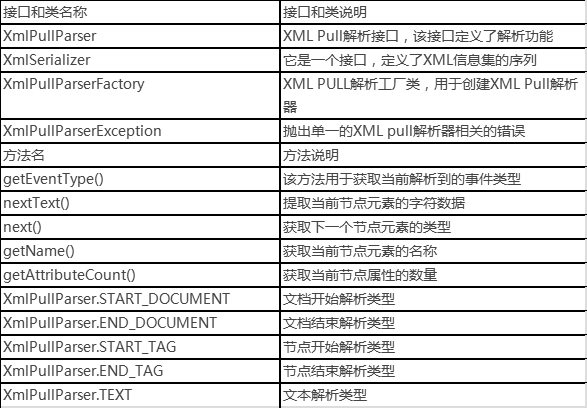
接下来我们将学习使用PULL解析XML的编程步骤,一般分为5个步骤,如下:
1、获取PULL解析工厂实例对象;2、使用XmlPullParserFactory的newPullParser()方法实例化PULL解析实例对象;3、设置需解析的XML文件流和字符编码;4、获取事件解析类型;5、循环遍历解析,当文档解析结束时结束循环;
然后,我们按照这5个步骤来完成Demo实例解析person.xml的工作(person.xml的内容上面已经列出),解析的关键代码是在Demo实例工程中的XmlTools类中,具体代码如下:
/**--------------PULL解析XML-------------------*/
/**
* @param mInputStream 需要解析的person.xml的文件流对象
* @param encode 设置字符编码
* @return mList Person对象集合
*/
public static ArrayList<Person> PullAnalysis(InputStream mInputStream,String encode){
ArrayList<Person> mList = null;
Person mPerson = null;
try {
//1、获取PULL解析工厂实例对象
XmlPullParserFactory mXmlPullParserFactory = XmlPullParserFactory.newInstance();
//2、使用XmlPullParserFactory的newPullParser()方法实例化PULL解析实例对象
XmlPullParser mXmlPullParser = mXmlPullParserFactory.newPullParser();
//3、设置需解析的XML文件流和字符编码
mXmlPullParser.setInput(mInputStream, encode);
//4、获取事件解析类型
int eventType = mXmlPullParser.getEventType();
//5、循环遍历解析,当文档解析结束时结束循环
while(eventType != XmlPullParser.END_DOCUMENT){
switch (eventType) {
//开始解析文档
case XmlPullParser.START_DOCUMENT:
mList = new ArrayList<Person>();
break;
//开始解析节点
case XmlPullParser.START_TAG:
if("person".equals(mXmlPullParser.getName())){
mPerson = new Person();
//获取该节点中的属性的数量
int attributeNumber = mXmlPullParser.getAttributeCount();
if(attributeNumber > 0){
//获取属性值
mPerson.setId(Integer.parseInt(mXmlPullParser.getAttributeValue(0)));
}
}else if("name".equals(mXmlPullParser.getName())){
//获取该节点的内容
mPerson.setUserName(mXmlPullParser.nextText());
}else if("height".equals(mXmlPullParser.getName())){
mPerson.setHeight(Float.parseFloat(mXmlPullParser.nextText()));
}else if("imageurl".equals(mXmlPullParser.getName())){
mPerson.setImageUrl(mXmlPullParser.nextText());
}
break;
//解析节点结束
case XmlPullParser.END_TAG:
if("person".equals(mXmlPullParser.getName())){
mList.add(mPerson);
mPerson = null;
}
break;
default:
break;
}
eventType = mXmlPullParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return mList;
}
现在我么已经分别使用SAX、DOM和PULL解析器解析person.xml的文件流后,结果返回Person对象的集合,我们的解析工作便完成了,接下来需要做的就是将解析结果以列表的方式展现在客户端界面上。那首先我们先来实现一下从网络服务端获取数据的网络访问代码,在工程中主要包含HttpRequest和MyAsynctask两个类,前者主要功能是执行网络请求,后者是进行异步请求的帮助类。首先看HttpRequest类的代码,如下:
/**
* 网络访问类
* @author AndroidLeaf
*/ public class HttpRequest {
/**
* @param urlStr 请求的Url
* @return InputStream 返回请求的流数据
*/
public static InputStream getInputStreamFromNetWork(String urlStr)
{
URL mUrl = null;
HttpURLConnection mConnection= null;
InputStream mInputStream = null;
try {
mUrl = new URL(urlStr);
mConnection = (HttpURLConnection)mUrl.openConnection();
mConnection.setDoOutput(true);
mConnection.setDoInput(true);
mConnection.setReadTimeout(15 * 1000);
mConnection.setConnectTimeout(15 * 1000);
mConnection.setRequestMethod("GET");
int responseCode = mConnection.getResponseCode();
if(responseCode == HttpURLConnection.HTTP_OK){
//获取下载资源的大小
//contentLength = mConnection.getContentLength();
mInputStream = mConnection.getInputStream();
return mInputStream;
}
} catch (IOException e) {
// TODO: handle exception
}
return null;
}
/**
* 得到图片字节流 数组大小
* */
public static byte[] readStream(InputStream mInputStream){
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[2048];
int len = 0;
try {
while((len = mInputStream.read(buffer)) != -1){
outStream.write(buffer, 0, len);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
if(outStream != null){
outStream.close();
}
if(mInputStream != null){
mInputStream.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return outStream.toByteArray();
}
接着实现MyAsynctask类的代码,如下:
/**
* 异步请求工具类
* @author AndroidLeaf
*/ public class MyAsynctask extends AsyncTask<Object, Void, Object> {
private ImageView mImageView;
private ImageCallBack mImageCallBack;
//请求类型,分为XML文件请求和图片下载请求
private int typeId;
//使用的XML解析类型ID
private int requestId;
/**
* 定义一个回调,用于监听网络请求,当请求结束,返回访问结果
*/
public HttpDownloadedListener mHttpDownloadedListener;
public interface HttpDownloadedListener{
public void onDownloaded(String result,int requestId);
}
public void setOnHttpDownloadedListener(HttpDownloadedListener mHttpDownloadedListener){
this.mHttpDownloadedListener = mHttpDownloadedListener;
}
public MyAsynctask(ImageView mImageView,ImageCallBack mImageCallBack,int requestId){
this.mImageView = mImageView;
this.mImageCallBack = mImageCallBack;
this.requestId = requestId;
}
@Override
protected void onPreExecute() {
// TODO Auto-generated method stub
super.onPreExecute();
}
@Override
protected Object doInBackground(Object... params) {
// TODO Auto-generated method stub
InputStream mInputStream = HttpRequest.getInputStreamFromNetWork((String)params[0]);
if(mInputStream != null){
switch ((int)params[1]) {
case Constants.TYPE_STR:
typeId = Constants.TYPE_STR;
return WriteIntoFile(mInputStream);
case Constants.TYPE_STREAM:
typeId = Constants.TYPE_STREAM;
return getBitmap(HttpRequest.readStream(mInputStream),
200, 200);
default:
break;
}
}
return null;
}
@Override
protected void onPostExecute(Object result) {
// TODO Auto-generated method stub
if(result != null){
switch (typeId) {
case Constants.TYPE_STR:
mHttpDownloadedListener.onDownloaded((String)result,requestId);
break;
case Constants.TYPE_STREAM:
mImageCallBack.resultImage(mImageView,(Bitmap)result);
break;
default:
break;
}
typeId = -1;
}
super.onPostExecute(result);
}
public Bitmap getBitmap(byte[] bytes,int width,int height){
//获取屏幕的宽和高
/**
* 为了计算缩放的比例,我们需要获取整个图片的尺寸,而不是图片
* BitmapFactory.Options类中有一个布尔型变量inJustDecodeBounds,将其设置为true
* 这样,我们获取到的就是图片的尺寸,而不用加载图片了。
* 当我们设置这个值的时候,我们接着就可以从BitmapFactory.Options的outWidth和outHeight中获取到值
*/
BitmapFactory.Options op = new BitmapFactory.Options();
op.inJustDecodeBounds = true;
Bitmap pic = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
int wRatio = (int) Math.ceil(op.outWidth / (float) width); //计算宽度比例
int hRatio = (int) Math.ceil(op.outHeight / (float) height); //计算高度比例
/**
* 接下来,我们就需要判断是否需要缩放以及到底对宽还是高进行缩放。
* 如果高和宽不是全都超出了屏幕,那么无需缩放。
* 如果高和宽都超出了屏幕大小,则如何选择缩放呢》
* 这需要判断wRatio和hRatio的大小
* 大的一个将被缩放,因为缩放大的时,小的应该自动进行同比率缩放。
* 缩放使用的还是inSampleSize变量
*/
if (wRatio > 1 && hRatio > 1) {
if (wRatio > hRatio) {
op.inSampleSize = wRatio;
} else {
op.inSampleSize = hRatio;
}
}
op.inJustDecodeBounds = false; //注意这里,一定要设置为false,因为上面我们将其设置为true来获取图片尺寸了
pic = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
return pic;
}
/**
* 将下载的XML文件流存储到手机指定的SDcard目录下
* @param mInputStream 需要读入的流
* @return String 返回存储的XML文件的路径
*/
public String WriteIntoFile(InputStream mInputStream){
if(isSDcard()){
try {
FileOutputStream mOutputStream = new FileOutputStream(new File(getFileName()));
int len = -1;
byte[] bytes = new byte[2048];
try {
while((len = mInputStream.read(bytes)) != -1){
mOutputStream.write(bytes, 0, len);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
if(mOutputStream != null){
mOutputStream.close();
}
if(mInputStream != null){
mInputStream.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return getFileName();
}
return null;
}
/**
* 检测SDcard是否可用
* @return
*/
public boolean isSDcard(){
if(Environment.getExternalStorageState().equals(Environment.MEDIA_MOUNTED)){
return true;
}else{
return false;
}
}
/**
* 获取需要存储的XML文件的路径
* @return String 路径
*/
public String getFileName(){
String path = Environment.getExternalStorageDirectory().getPath() +"/XMLFiles";
File mFile = new File(path);
if(!mFile.exists()){
mFile.mkdirs();
}
return mFile.getPath() + "/xmlfile.xml";
}实现完网络请求的功能后,我们就可以从服务端获取到person.xml的文件流,然后再分别用SAX、DOM和PULL解析器将文件流解析(在上面介绍这几种解析器时已经实现了解析的代码,在工程中的XmlTools类中)成对应的Java对象集合,最后将Java对象集合以列表的形式展现在客户端界面上,那接下来我们将实现该功能。在工程中主要包含MainActivity、MyAdapter和ImageCallBack类,首先实现MainActivity的代码,如下:
public class MainActivity extends ListActivity implements HttpDownloadedListener{
private ProgressDialog mProgressDialog;
//需要解析的节点名称
private String nodeName = "person";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_list);
//初始化数据
initData();
}
public void initData(){
mProgressDialog = new ProgressDialog(this);
mProgressDialog.setProgressStyle(ProgressDialog.STYLE_SPINNER);
mProgressDialog.setTitle("正在加载中.....");
mProgressDialog.show();
//首次进入界面是,默认使用SAX解析数据
downloadData(this,Constants.XML_PATH,Constants.REQUEST_PULL_TYPE,null,null,Constants.TYPE_STR);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// TOdO Auto-generated method stub
getMenuInflater().inflate(R.menu.main, menu);
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
// TOdO Auto-generated method stub
int requestId = -1;
switch (item.getItemId()) {
case R.id.sax:
requestId = Constants.REQUEST_SAX_TYPE;
break;
case R.id.dom:
requestId = Constants.REQUEST_DOM_TYPE;
break;
case R.id.pull:
requestId = Constants.REQUEST_PULL_TYPE;
break;
default:
break;
}
downloadData(this, Constants.XML_PATH, requestId, null, null, Constants.TYPE_STR);
mProgressDialog.show();
return super.onOptionsItemSelected(item);
}
@Override
public void onDownloaded(String result,int requestId) {
// TODO Auto-generated method stub
FileInputStream mFileInputStream = null;
try {
mFileInputStream = new FileInputStream(new File(result));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ArrayList<Person> mList = null;
switch (requestId) {
case Constants.REQUEST_SAX_TYPE:
mList = XmlTools.saxAnalysis(mFileInputStream,nodeName);
break;
case Constants.REQUEST_DOM_TYPE:
mList = XmlTools.domAnalysis(mFileInputStream);
break;
case Constants.REQUEST_PULL_TYPE:
mList = XmlTools.PullAnalysis(mFileInputStream,"UTF-8");
break;
default:
break;
}
MyAdapter myAdapter = new MyAdapter(this, mList);
setListAdapter(myAdapter);
if(mProgressDialog.isShowing()){
mProgressDialog.dismiss();
}
}
//执行网络下载代码
public static void downloadData(HttpDownloadedListener mDownloadedListener,String url,int requestId,ImageView mImageView,ImageCallBack mImageCallBack,int typeId){
MyAsynctask mAsynctask = new MyAsynctask(mImageView,mImageCallBack,requestId);
mAsynctask.setOnHttpDownloadedListener(mDownloadedListener);
mAsynctask.execute(url,typeId);
}
}
然后再实现界面的适配器类–MyAdapter,具体代码如下:
/**
* 数据界面展示的适配器类
* @author AndroidLeaf
*/ public class MyAdapter extends BaseAdapter {
private Context mContext;
private ArrayList<Person> mList;
private Bitmap[] mBitmaps;
public MyAdapter(Context mContext,ArrayList<Person> mList){
this.mContext = mContext;
this.mList = mList;
mBitmaps = new Bitmap[mList.size()];
}
@Override
public int getCount() {
// TODO Auto-generated method stub
return mList.size();
}
@Override
public Object getItem(int position) {
// TODO Auto-generated method stub
return mList.get(position);
}
@Override
public long getItemId(int position) {
// TODO Auto-generated method stub
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
// TODO Auto-generated method stub
ViewHolder mHolder;
Person mPerson = mList.get(position);
if(convertView == null){
convertView = LayoutInflater.from(mContext).inflate(R.layout.item_list, null);
mHolder = new ViewHolder();
mHolder.mTextView_id = (TextView)convertView.findViewById(R.id.item_id);
mHolder.mTextView_name = (TextView)convertView.findViewById(R.id.item_name);
mHolder.mTextView_height = (TextView)convertView.findViewById(R.id.item_height);
mHolder.mImageView_image = (ImageView)convertView.findViewById(R.id.item_image);
//为Imageview设置TAG,作为每一个ImageView的唯一标识
mHolder.mImageView_image.setTag(mPerson.getImageUrl());
convertView.setTag(mHolder);
}else{
mHolder = (ViewHolder)convertView.getTag();
}
mHolder.mTextView_id.setText(String.valueOf(mPerson.getId()));
mHolder.mTextView_name.setText(mPerson.getUserName());
mHolder.mTextView_height.setText(String.valueOf(mPerson.getHeight()));
/**
* 解决异步加载过程中Listview列表中图片显示错位问题
*/
//判断当前位置的ImageView和是否为上次执行加载操作的ImageView,若false则重置上次加载的那个Imageview中的图片资源
if(!mPerson.getImageUrl().equals(String.valueOf(mHolder.mImageView_image.getTag()))){
mHolder.mImageView_image.setImageResource(R.drawable.ic_launcher);
}
//重新为ImageView实例设置TAG
mHolder.mImageView_image.setTag(mPerson.getImageUrl());
if(mBitmaps[position] == null){
//执行异步加载图片操作
MainActivity.downloadData((HttpDownloadedListener)mContext, Constants.BASE_PATH + mPerson.getImageUrl(), -1,
mHolder.mImageView_image, new MyImageCallBack(position,mPerson.getImageUrl()), Constants.TYPE_STREAM);
}else{
mHolder.mImageView_image.setImageBitmap(mBitmaps[position]);
}
return convertView;
}
class ViewHolder{
TextView mTextView_id;
TextView mTextView_name;
TextView mTextView_height;
ImageView mImageView_image;
}
class MyImageCallBack implements ImageCallBack{
int index = -1;
String imageUrl = null;
public MyImageCallBack(int index,String imageUrl){
this.index = index;
this.imageUrl = imageUrl;
}
@Override
public void resultImage(ImageView mImageView, Bitmap mBitmap) {
// TODO Auto-generated method stub
//判断当前显示的ImageView的URL是否与需要下载的图片ImageView的URL相同
if(imageUrl.equals(String.valueOf(mImageView.getTag()))){
mBitmaps[index] = mBitmap;
mImageView.setImageBitmap(mBitmap);
}
}
}
}观察上面的代码,在实现适配器类时,由于我们需要异步下载图片,因此在图片绑定和显示时由于列表项焦点的不断变换和图片数据加载的延迟会导致ListView中的图片显示错位的问题,为了解决该问题,我们采取对ImageView设置TAG来解决了图片错位问题,那要明白其中的原理,就必须对Listview加载item view列表项的实现机制比较清楚,由于该问题不是本文的重点,因此在此不便细讲,有兴趣的读者可以学习本博客的另一篇文章《Android异步加载数据时ListView中图片错位问题解析》,希望对你有所帮助。在实现图片异步加载时,程序中还使用到了一个非常有用的接口–ImageCallBack,该接口主要作用是将异步下载的图片设置到对应的Imageview控件中,该接口的具体代码如下:
public interface ImageCallBack {
public void resultImage(ImageView mImageView,Bitmap mBitmap);
}
当然,还有常量Constants类和Entity对象Person类。Constants类的具体的代码:
/**
* 网络请求的Url地址及一些常量
* @author AndroidLeaf
*/ public class Constants {
//基路径
public static final String BASE_PATH = "//10.0.2.2:8080/09_Android_XMLServer_Blog/";
//person.xml网络请求路径
public static final String XML_PATH = BASE_PATH + "xmlfile/person.xml";
//使用SAX解析的标签类型
public static final int REQUEST_SAX_TYPE = 0;
//使用DOM解析的标签类型
public static final int REQUEST_DOM_TYPE = 1;
//使用PULL解析的标签类型
public static final int REQUEST_PULL_TYPE = 2;
//请求person.xml文件标签
public static final int TYPE_STR = 1;
//请求图片文件标签
public static final int TYPE_STREAM = 2;
}
Person类的代码如下:
public class Person {
private int id;
private String userName;
private float height;
private String imageUrl;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public float getHeight() {
return height;
}
public void setHeight(float height) {
this.height = height;
}
public String getImageUrl() {
return imageUrl;
}
public void setImageUrl(String imageUrl) {
this.imageUrl = imageUrl;
}
@Override
public String toString() {
return "Person [id=" + id + ", userName=" + userName + ", height="
+ height + ", imageUrl=" + imageUrl + "]";
}
}全部的编码都已经完成,最后我们再Android模拟器上运行我们的Demo实例工程,运行及操作的效果图如下:
SAX、DOM和PULL解析器的比较
SAX解析器的特点:SAX解析器解析速度快、高效,占用内存少。但它的缺点是编码实现比其它解析方式更复杂,对于只需解析较少数量的XML文件时,使用SAX解析显得实现代码比较臃肿。
DOM解析器的特点:由于DOM在内存中是以树形结构存放的,那虽然检索和更新效率比较高,但对于使用DOM来解析较大数据的XML文件,将会消耗很大内存资源,这对于内存资源比较有限的手机设备来讲,是不太适合的。
PULL解析器的特点:PULL解析器小巧轻便,解析速度快,简单易用,非常适合在Android移动设备中使用,Android系统内部在解析各种XML时也是用PULL解析器,Android官方推荐开发者们使用Pull解析技术。Pull解析技术是第三方开发的开源技术,它同样可以应用于JavaSE开发。
根据上面介绍的这些解析器的特点我们可在不同的开发情况下选择不同的解析方式,比如说,当XML文件数据较小时,可以选择DOM解析,因为它将XML数据以树形结构存放在内存中,在占用不多的内存资源情况下检索和更新效率比较高,当XML文件数据较大时,可以选择SAX和PULL解析,因为它们不需要将所有的XML文件都加载到内存中,这样对有限的Android内存更有效。SAX和PULL解析的不同之处是,PULL解析并不像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档数据较大但只需要文档的一部分时,XML PULL解析器则是更为有效的方法。
总结:本文学习了在Android开发中解析XML文件的几种常用解析方式,这几种解析方式各有优缺点,我们应根据不同的开发需求选择合适的解析方式。最后总结一下在Android解析XML所需掌握的主要知识点:(1)XML的特点以及结构组成形式,掌握如何编写XML文件;(2)了解SAX、PULL和DOM解析器的特点,并掌握在Android中使用这三种解析方式的使用;(3)比较三种解析器的特点,学会在不同情况下选择合适的解析方式。
本文由职坐标整理并发布,希望对同学们有所帮助。了解更多详情请关注职坐标移动开发之Android频道!
 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




